Terminology
What is Machine Learning
Machine learning is an application of artificial intelligence (AI) that provides systems the ability to automatically learn and improve from experience without being explicitly programmed.
What is the difference amongs Artifical Intelligence (AI), Machine Learning (ML), Data Mining and Pattern Recognization
Artificial Intelligence human-like intelligence displayed by software and/or machines, is the broader concept of machines being able to carry out tasks in a way that we would consider “smart”, AI concentrated on mimicking human decision making processes and carrying out tasks in ever more human ways
Machine learning algorithms that can learn from data to make predictions, focuses on the development of computer programs that can access data and use it learn for themselves.
Data mining is the process of finding anomalies, patterns and correlations within large data sets to predict outcomes, the process of digging through data to discover hidden connections and predict future trends, knowledge discovery in databases (KDD)
- descriptive analytics and predictive analytics are used for unsupervised learning and supervised learning
Pattern recognition the automated recognition of patterns and regularities in data
Supervised Machine Learning
Starting from the analysis of a known training dataset by given "right answers", the trained model is able to make predictions about the output values.
Unsupervised Machine Learning
Classify or label data without given "right answers"
Semi-supervised machine learning
Use both labeled and unlabeled data for training
Reinforcement machine learning
a learning method that interacts with its environment by producing actions and discovers errors or rewards
Classification and Regression, supervised learning
classification is about predicting a label
regression is about predicting a quantity
Clustering and Associative, unsupervised learning
clustering the data based on relationships among the variables in the data
Association analysis
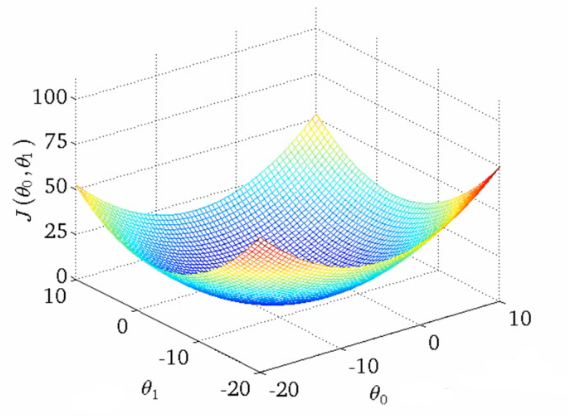
Convex Function
In mathematics, a real-valued function defined on an n-dimensional interval is called convex (or convex downward or concave upward) if the line segment between any two points on the graph of the function lies above or on the graph, in a Euclidean space (or more generally a vector space) of at least two dimensions.
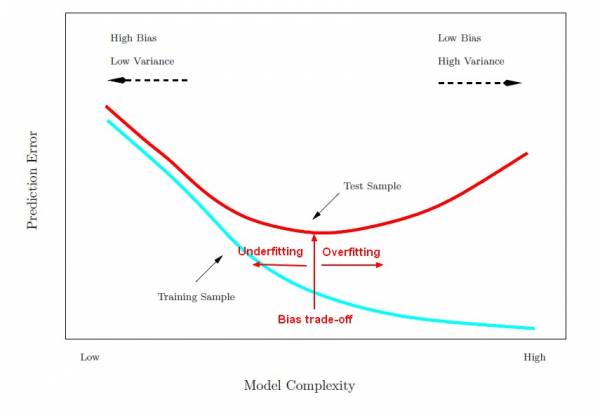
Underfitting and Overfitting
Bias referes to the error that is introduced by approximating a real-life problem
Variance is due to the model's excessive sensitivity to small variations in the training data, refers to the amount by which factor would change if we estimated it using a different training data set
Irreducible error is due to the noisiness of the data itself. The only way to reduce this part of the error is to clean up the data
Higher the degrees of freedom, may cause overfitting, low bias, high variance
Lower the degrees of freedom, may cause underfitting, high bias, low variance
Avoid Underfitting and Overfitting
Cross Validation
- Overfitting, performs well on training data but generalizes poorly according to the cross-validation metrics
- Underfitting, performs poorly on both training data and the cross-validation metrics
Learning Curves
- Plots of the model's performance on the training set and the validation set as a function of the training set size
- Underfitting, both curves have reached a plateau, they are close and fairly high
- Overfitting, there is a gap between the curves, the model performs significantly better on the training data than on the validation data